Implementing data integration in your organization involves more than just purchasing software or writing some code. It requires designing systems, engaging with personnel, changing workflows, putting technical processes in place, and generally overseeing a lot of moving parts. Attaining perfection is unrealistic. However, knowing common pitfalls to avoid ahead of time will go a long way towards making your project as smooth and successful as possible.
1. Collecting Everything
If you’re just getting started with bringing your data together, you may be tempted to collect every last piece of data to build out a comprehensive data pipeline. But that’s rarely the best way to begin. It’s like trying to run a marathon without any practice on your first try. There’s a good chance you’ll be overwhelmed, and it’s unlikely you’ll complete it in a reasonable amount of time.
It’s far better to start with a small set of data, and add to it steadily as your organization’s needs increase. Otherwise you’ll expend a lot of effort filling your pipeline with data that you may never use, wasting valuable resources. If your infrastructure is cloud-based, it could also mean paying for throughput you don’t really need.
By starting small, not only will your project be more manageable but it will be easier to troubleshoot if something’s not working properly. Building a data pipeline can be a complex process, and you’re bound to make mistakes–or at the very least fail to foresee obstacles. If you end up needing to overhaul what you’ve built, you don’t want to have to rebuild something massive. Your aim should be to test and prove your pipeline well before it starts getting too complex. As complexity increases, the amount of troubleshooting required to pinpoint an issue increases exponentially, making it much more difficult to resolve issues.
To simplify your approach, identify one specific outcome you want to accomplish. For example, if your goal is to create a dashboard, decide what visualizations you want to show, then identify the data elements you need to make that happen. Which data sources do you absolutely need to retrieve data from? Within each data source, which fields are essential? Stay focused on need-to-have and avoid nice-to-have (i.e., fields you may never use).
A helpful model is a development discipline that guides many startup businesses known as the Minimum Viable Product (MVP). To develop an MVP, a company focuses on the bare minimum features and quickest path to create a functional product. Thinking in terms of an MVP, figure out the minimum data you need to achieve your outcome, then build out your data pipeline. Guard against any scope creep. In the end, you will have established a solid foundation for your data integration–a simple data pipeline that you’ll confidently be able to fill with more data as your organization’s needs increase.
2. Choosing the Wrong Data Model
Early on in building your data pipeline, you’ll need to decide on the data model for your target system (the system you’ll be pushing your data into). Since your target data model must accommodate data from all of your sources, this step takes some thoughtful planning, as it will determine how much you’ll need to transform your data. It is almost certain that you will need to transform your data at least somewhat to take into account the differences in your sources.
Often the way data is stored in your sources will not fit the outcome you want to achieve. A common scenario is a flat data arrangement that’s sufficient for the purposes of the source system, but does not work well for analytics. For example, let’s say you have a database that stores fees for a transaction, where each transaction can have anywhere from zero to a handful of fees. A flat data model would have separate fields for each fee: Fee1, Fee2, Fee3, and so on.

While this might have been a logical choice for the source system, it’s a poor design for your target if your goal is to display analytics that depend on calculations of these fees. What if you want to add up all the fees? Your formula is going to be a little messy. And if you want to total only the “PD” fees across all transactions, now you have a real headache!
It’s far better to transform the data by putting these fees in a separate table, where they will be much easier to work with.
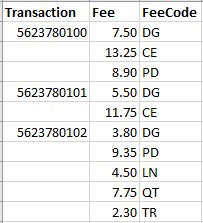
In this format, you can easily use standard analytics functions like SUM to perform the calculations you need. This is a simple example, but it illustrates an important principle that applies to each step you take in building your data pipeline.
Here’s the principle: When building your data pipeline, the key is to think in reverse. In other words, start by considering the output you need. Then work backwards. In our fee example, let’s say your desired output is a chart that shows the highest fees, grouped by fee code. With that output in mind, you can see that keeping the same data model as your source will make generating such a simple chart much more difficult than it needs to be. Recognizing this issue ahead of time will guide you in choosing the correct design for your data model.
3. Assuming High Quality Data
Hands down, the most critical aspect of data management is data quality. The familiar expression “garbage in, garbage out” is never truer than it is in the world of data. It makes no difference how clever your data transformations are, how rock solid your data model is, or how slick your visualizations are if the output of your pipeline is bad data.
Achieving high quality data requires doing data quality work. There’s no way around it. That means validating data, auditing data processes, monitoring data feeds, and taking corrective actions. Without this due diligence, making any assumptions about the quality of your data is dangerous and will detrimentally impact your organization.
Let’s take the example of data coming from a third-party vendor. Here are some common, problematic assumptions to avoid:
- Assuming the vendor is delivering what they say they are. In almost all cases, you don’t have visibility into the vendor’s back-end systems, which means you don’t know what hiccups may be occurring on their side. You may see that the vendor’s feed is coming through on schedule, but without taking the time to vet the data, you won’t know if that feed contains 100% of the data you’re expecting. Put in the work to review and validate your feeds from the start. Then, make sure you have a process to check the feeds on a regular basis going forward.
- Assuming the vendor’s data feeds are error-free. It is nearly impossible for any system to be error-free all the time. Whether due to a data entry error, a connection glitch, a programming bug, or any number of other issues, errors will occur. Have a plan to deal with them. This might include maintaining backups, running redundant systems, or at the very least having a process to back out the erroneous data and re-ingest the corrected data. You’ll also want to have something in place to detect the errors. Ideally, this would be an automated process that spots an error as soon as it occurs, but when you’re just starting out, it can be as simple as having someone familiar with the data review it on a regular basis.
- Assuming the vendor’s data structure won’t change. In an ideal world, your vendor would never change their data structure without first warning you. In the real world, however, it happens too often. Depending on how robust your data integration code or platform is, the consequences can range from having to update some metadata files to dealing with catastrophic failure of your data pipeline. At the very least, it is worth building into your data ingestion process notifications to alert you if the data structure changes. Even better is to put in place a system with the resilience to bend-but-not-break in this scenario, giving you time to manage the crisis.
- Assuming the vendor will have 100% uptime. “Always on” is a noble goal . . . but impossible to execute in the real world. Even if your vendor were able to achieve it, in between your vendor and your organization are likely several systems (servers, networks etc.) that will not have 100% uptime. This means your data pipeline needs to be stable enough to withstand the outages you will inevitably face. At a minimum, you should ensure that when the vendor’s system goes down, you don’t end up with holes in your data.
4. Not Understanding Your Data
Next to data quality, the most important part of data management is understanding your data. If that sounds like a no-brainer, it is. Yet data literacy remains a significant issue affecting almost every organization. The bottom line is that misunderstanding your data is equivalent to having bad data. Put another way, drawing incorrect conclusions because you have bad data is really no different than drawing incorrect conclusions because you don’t understand what your data represents.
Although there are many facets to data literacy, a frequent source of data literacy issues often lies in the fact that in a typical organization, data lives in “silos”–different systems that correspond with different departments. Your data integration will bring all of that data together into a single location, where someone can then create visualizations and run reports on the data. The problem is that it’s highly unlikely the person tasked with creating those analytics will have a complete understanding of every data point from every department.
Classic examples are industries like accounting or logistics, where the data contained in a numeric field depends on how an organization sets up their accounting or what goods the organization imports. That means the name of the field alone isn’t sufficient to understand the data. In cases like these, only a subject matter expert (SME) will know precisely what data the field contains. Unless the person creating a visualization finds and consults the SME, that person will not have a full understanding of the data. Frankly speaking, we humans are lazy. Tracking down the owner of the data takes time, and it’s easier to make an assumption about a piece of data than it is to put in the effort to understand it. The result is that any visualization using that piece of data will be at best misleading, and at worst, wildly inaccurate.
To avoid this issue, document your data as you build out your data pipeline. Ideally, you’ll want to develop a data catalog that defines exactly what each piece of data represents and make this resource easily accessible across your organization. Granted, no one likes to create documentation. But in the long run, it’s the only way to ensure your reports and charts consistently provide accurate insights.
5. Unwillingness To Change
Data management decisions should be thought of in the context of streamlining, optimizing and automating data processes. It’s helpful to focus on the dual goals of increasing accuracy of insights drawn from your data and decreasing resources required to maintain such accuracy. However, the reality for most organizations is that doing so requires overcoming the “if it ain’t broke, don’t fix it” inertia.
One area usually in need of (but resistant to) change is manual intervention in data management. It’s not uncommon to hear someone say, “We can just export it to Excel and fix it there, it’s what I usually do anyways.” Extrapolate this manual process across your entire organization, and you can see how old (bad) habits like these add up to significant labor hours. Here’s the truth: Almost anything that needs to be done with data can be automated. Program it once, and you never have to worry about it again.
Workflow is another area often ripe for change. Data integration, while a big win overall for an organization, has always faced the challenge of accurately lining up data from different source systems. A typical example is found in the world of human services, where an organization commonly has a call center system that’s separate from its main client system. Separate systems mean separate IDs for the same client. When bringing the data together, matching on names will not work (because not always unique), and using the phone number captured by the call system–although one step better–still fails because many clients make calls from a non-unique number, such as a hospital, hotel, or safe house. The simplest solution in this scenario is to add a step to the workflow by looking up the client ID in the main system and entering it in a field in the call center system. With a common ID in both systems, data will correctly match up when the data integration runs.
Wrap Up
Data integration should be an integral part of any organization’s overall data management strategy. Implementation often presents challenges, however, especially when an organization is first starting out. There are many aspects to consider, and every organization’s data landscape will look a little different, so there is no one-size-fits-all approach. The key is to start simply and build a solid foundation first, before trying to tackle all of your data. Focus on a single goal, and limit your data pipeline to only the data necessary to achieve that goal. Once you have a proven process in place, you’ll be able to add data to meet the growing needs of your organization.