One of my recent client projects reminded me how complex the process of data integration can be. On its face, the task was simple: Connect to a vendor’s API to send and receive data. Data would be sent from the client’s web portal, and received data would ultimately land in their data warehouse.
The vendor is a relatively small company that provides data for a niche vertical. Their API landscape consists of a mix of mostly reliable, established endpoints as well as a few less-than-robust, “sure-we-can-spin-that-up-for-you” ones. Not exactly the stuff dreams are made of when you’re building a data pipeline. Let’s just say there have been some hiccups along the way.
Working with Older Systems
While developing against one of the vendor’s ad hoc endpoints, I ran into a challenge. My client needed to run the ingestion code on an in-house Windows server with a decade-old OS. Due to its vintage, the server’s security component didn’t fully implement the secure protocols used by the vendor.
More specifically, the Win server supported the right secure protocol version, but lacked any of the cipher suites in common with the vendor’s secure certificate.
What’s a cipher suite you say? (You may regret this…) A cipher suite defines the methods for authentication and encryption a server uses to connect with another server and send data securely. Here’s a visual:
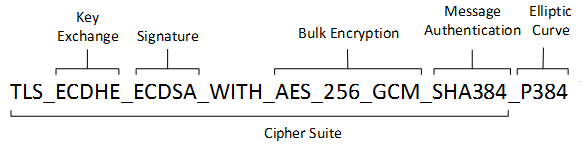
Because the Win server didn’t have the right cipher suite, it couldn’t negotiate the “handshake” to establish secure communication with the vendor’s server.
I wondered why I didn’t run into this issue during development. Then I realized that my development machine was running the latest Windows OS, which fully supported the latest cipher suites. But when I pushed the code to the Win box with the decade-old OS, it broke.
Thinking Outside the Box
After a whole lot of wheel-spinning on Google–and finally reaching out to a colleague–I figured out that I could solve the issue by setting up something called a “reverse proxy” using a server that offers the right cipher suite support.
My client didn’t have any other servers running a newer version of Windows with the necessary cipher suite, which meant I had to find something else. My colleague suggested spinning up an instance of nginx on the same Win machine.
The plan: The nginx server would function as a middleman and receive a non-secure request from my application, then pass it through to the vendor’s server as a secure communication. This avoided the Win server’s outdated security components and made use of the up-to-date ones offered by nginx. And since the initial, non-secure communication was happening within the same server, there were no issues with transmitting data insecurely.
Voila, issue resolved! Or so I thought.
It worked great for phase one of my project, which pulled data from the vendor’s API. The problem came when I needed to push data.
The vendor set up a new endpoint in their sandbox environment to allow me to test the push. As with my original application, everything worked smoothly on my development machine, but when I ran the application from the Win server, I saw into the same security errors I encountered before installing the proxy server.
How could the push be different from the pull? Thinking that maybe somehow the push required another level of authentication, I chased that hypothesis to a bunch of dead ends in Google.
Looking Under the Hood
I finally decided I needed to see exactly what the two servers were saying to each other, so I configured my application to log a detailed trace of the entire communication from beginning to end. I then went line by line through the logs trying to determine the point of failure.
The root issue turned out to be that the vendor’s server was responding with a 307 redirect message. Unbeknownst to me, a Windows library in my code handed the redirect in the background by receiving the redirect header with the new location and silently reconnecting to the new location directly, bypassing the nginx proxy.
This effectively put me back at square one: Trying to connect directly to the vendor’s server without having a compatible cipher suite. Argh.
After more Googling (and yes, a few more texts to my colleague), I figured out a solution. Two actually. I could either: 1) Configure nginx to rewrite the redirect and re-route back through the proxy, or 2) Just point the proxy directly to the redirect location. I went with the second option to keep it simple–and to save the round-trip caused by the redirect.
Problem solved at last. But all of that took a long time.
Wrap Up
My point in sharing this is to show that while the concept of data integration is elegant in theory, in practice it’s not always straightforward.
Connecting to an API to push and pull data should be a home run. In the real world, however, there are many individual pieces to line up for any data integration project, and almost always a few hurdles along the way. It’s helpful to manage expectations by understanding the complexity upfront and employing the resources you need to ensure successful implementation of your data pipeline.